

InstructGPT can execute more specific tasks
GPT-3 demonstrated to be the most powerful language A.I. algorithm able to write any genre of text: from articles to songs but also program languages for coding. However, GPT-3 is not free from defects or strange behaviors coming from bias that generate misinformation.
Although it’s suitable for a wide range of linguistic jobs, it’s hard to get something specific from it because you can’t define specifically what you want to achieve. A prompt engineering approach seemed the solution because it allows giving an input explicitly since the description of a task is embedded in the command, for example, a question or an order but it’s quite laborious for most of the users.
OpenAI has now solved this shortcoming introducing a new version of the GPT family they recommend using for all language tasks instead of the original GPT-3.
This version of GPT-3 (previously known as InstructGPT) is optimized to follow instructions, instead of predicting the most probable word. This not only makes them easier to operate for the majority of people because prompt engineering is no longer required, but it also makes the models more reliable and functional. The quality of the completions isn’t as reliant on the prompt as it was in the original GPT-3 models, preventing the model from making too many human-made errors.
We could say GPT-3 works well only when following indirect or implicit instructions. You never tell GPT-3 what to do directly, only implicitly. In contrast, InstructGPT can follow explicit instructions.
OpenAI, on the other hand, did not stop there. InstructGPT is not just far superior to GPT-3 in following instructions, but it is also more in line with human intent. This is the challenge of A.I. alignment that expresses the difficulties of creating A.I. systems that recognize our values, beliefs, and desires and act in a way that does not interfere with them, even if we make mistakes in our definitions.
In order to convert GPT-3 models to InstructGPT models, OpenAI developed a three-step technique.
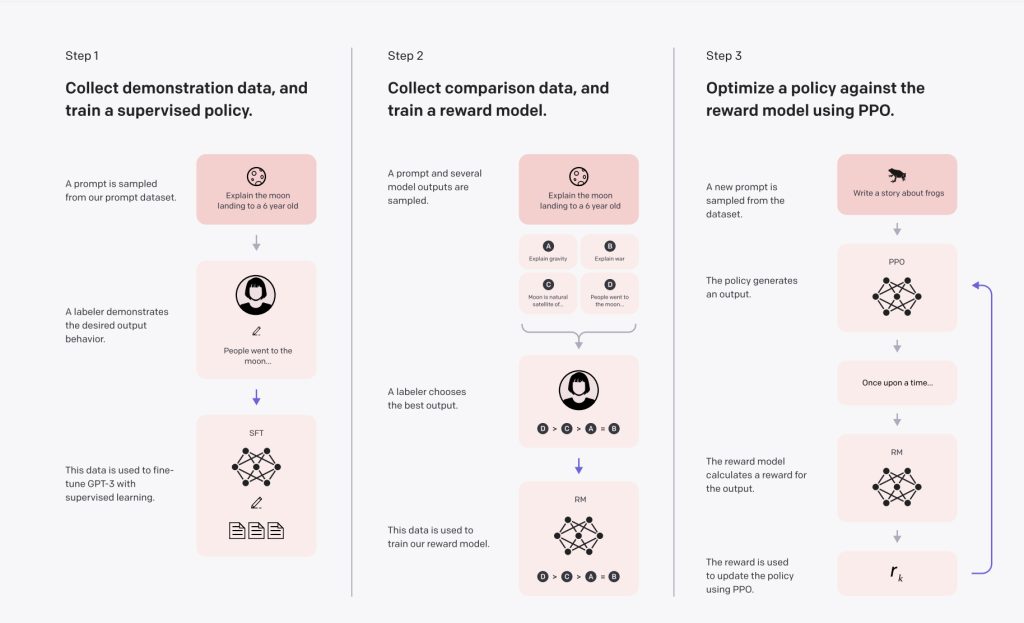
Fine-tuning the model is the initial stage for specializing GPT-3 in a specific activity. To do so, they created a dataset that included prompts and completions in the form of instruction-following data. They created a new model named SFT (supervised fine-tuning) after training GPT-3 on this dataset, which provided a baseline for comparing the original GPT-3 with the finished InstructGPT. This model was already better to GPT-3 in terms of following instructions, although it’s not necessarily aligned with human preferences.
In the following two steps, they used a reinforcement learning methodology they developed with DeepMind dubbed RLHF (reinforcement learning with human feedback) to align the model with the human purpose.
The second stage is to create a reward system (RM). To translate it into the RM, they fine-tuned a GPT-3 model using a comparative dataset of 33K prompts (not the same one they used to train SFT). The comparison dataset is made up of pairs of prompts with multiple completions per prompt (4–9), ranked by the human labeler from best to worst in terms of preference. When given a cue, the goal was for the RM to learn which completions humans prefer.
In the final phase, they used reinforcement learning to fine-tune an SFT model that had already been fine-tuned with the demonstration dataset. Because it employs a proximal policy optimization approach, the final model (InstructGPT), is also known as PPO-ptx in the study (ptx means pre-training mix because the last fine-tuning phase also uses data from the GPT-3 pre-training dataset) (PPO). The RM is used as the reward function in the PPO algorithm (this is how they teach InstructGPT from human feedback).
The final step’s fine-tuning procedure is as follows: When InstructGPT is presented with a prompt, it responds with a completion. The outcome is forwarded to the RM, who determines the award. The reward is given to the InstructGPT model in order for it to update the policy and get closer to the result that humans would wish to see.
In short, GPT-3 is fine-tuned to follow instructions first and then fine-tuned to accord with human preference based on human feedback. That’s InstructGPT.
GPT-3’s goal was simple: “get the most probable word given the data you’ve been fed” applying well-known machine learning and statistical techniques. However, it’s hard to define what’s helpful and harmless for humans. OpenAI intended to construct a target that could include both explicit (following instructions) and implicit (as defined by Amanda Askell and others) intentions: They desired a model who was helpful, honest, and harmless.
In the context of language models, honesty is hard to define since this behavior correlates with internal beliefs, which are opaque in language models. The same is for what’s harmful.
So labelers were directed to prioritize helpfulness to the user in training, even if the users explicitly desired a potentially harmful answer, and truthfulness and harmlessness in assessment, which they sought to improve during the process, to avoid these uncertainties.
InstructGPT models are closer to people than GPT-3, although there is a great deal of variability within the term “humans” that isn’t reflected in InstructGPT’s behavior. The model is in line with the preferences of the labelers and OpenAI researchers, and thus the organization as a whole, but how about the rest of the world? In a discussion, the company acknowledged the problem: “We are not claiming that researchers, the labelers we hired, or our API customers are the right source of preferences”.
To decrease bias in the alignment, OpenAI established a set of labeler selection criteria. The most important requirement was that labelers be sensitive to the preferences of various demographic groups.
But it’s quite unlikely that this set of labelers reflects our society’s diversity. Furthermore, employing the average to determine alignment is the contrary of real alignment, which implies that the model knows individual and group preferences precisely by how they differ from those of other persons and groups. Because the majority has more weight in the model’s final choice, average alignment could muddle minorities’ preferences.
Creating a model that is aligned with a sub-group of people is undeniably a significant step toward safer and more dependable models. However, we must remember that humans are incredibly different when working on A.I. alignment. How can we ensure that an A.I. model is aligned with everyone it interacts with in a non-harmful way? As OpenAI argues, the only logical starting point is to have at least one labeler representing each group, or a model suited for each group.
However, other issues arise, such as how do we define groups? Depending on ethnicity, gender, age, country, religion, and so on? How do we ensure that models designed for a certain group do not have a negative impact on society as a whole? These are unanswered problems, and they should be thoroughly considered before using biased models in the name of alignment.
They chose to test the models against TruthfulQA, a standard that analyzes “how models mimic human falsehoods,” to see how “honest” they are. They discovered that InstructGPT provides twice as many accurate responses as GPT-3. They also put the models through their paces in closed-domain QA and summarization tasks, finding that InstructGPT hallucinates half as much as GPT-3 (21% vs 41%). These are the default outcomes: the models do not need to be trained to behave honestly, which relieves the user of the responsibility of ensuring that the models are appropriately prompted.
They tested the models against the RealToxicityPrompts dataset to see how harmful they were, by discovering that InstructGPT is less toxic than GPT-3 when told to be respectful, especially toxic when not told, and substantially more toxic when told to be biased. This means that those who want to avoid toxicity will be able to do so more effectively with InstructGPT, but those with malicious intentions will find it simpler to hurt others with InstructGPT.
The new model isn’t necessarily safer than GPT-3, but it is more capable of following the user’s goal, which isn’t always good. Increasing the capacity of the models is a step forward in terms of performance, but not always in terms of safety. So it may be easier to create convincing misleading or nasty or abusive content using these models.
These findings support the hypothesis that aligning InstructGPT to a highly narrow group of people does not improve its behavior toward minorities and discriminatory groups. Therefore different labelers would result in a different outcome.
Finally, researchers discovered that models fine-tuned to optimize alignment with human labelers suffered from a performance penalty known as an “alignment tax”. As a result, InstructGPT outperforms GPT-3 on various public NLP datasets. They revised the fine-tuning technique and established the model PPO-ptx to compensate for the drop in performance. Reinforcement learning is used to fine-tune this model by integrating gradients from the reward model with updates from the original data used to pre-train GPT-3. As a result, PPO-ptx (InstructGPT) is more capable on NLP benchmarks than its brother, PPO, but less aligned.
Ultimately, InstructGPT is not without flaws. It can disobey orders, have hallucinations, produce harmful and biased outputs, and offer extended responses to small questions… The same issues that plagued GPT-3 models continue to affect the InstructGPT version (performance-related problems are less common, but safety-, toxicity-, and bias-related problems could be more common).
Pros and cons
InstructGPT outperforms GPT-3 in terms of performance. Not in terms of NLP benchmarks (where GPT-3 frequently outperforms InstructGPT), but it is better tailored to human preference, which is a stronger indicator of real-world performance. Thanks to a reinforcement learning model that allows it to learn from human feedback, InstructGPT is better aligned with human aim.
There’s no need to connect with InstructGPT through implicit or indirect prompt strategies because it can follow explicit instructions. This alleviates the strain on users who are unfamiliar with the operation of generative language models. This is an approach to democratizing these models (although other barriers like the high cost and not being available in some countries remain).
InstructGPT outperforms GPT-3 when it comes to executing implicit instructions, making it more accurate, useful, and safe as long as the user wants it to be. When prompted to be respectful, it’s likewise less toxic than GPT-3. These attributes make it more useful for well-intentioned individuals who will be able to get the most out of the model while worrying less about uncontrollable errors.
However, a bad user might exploit this to make the model less accurate and useful, as well as more dangerous. The damage could be higher because the model is more powerful than GPT-3.
InstructGPT can be more harmful if it is instructed to be biased for the same reason. When asked to be biased, the increase in toxicity is greater than when asked to be respectful. In general, the models are more biased than GPT-3. One probable explanation is because, as the authors suggest, InstructGPT is more assured of its responses regardless of whether it uses stereotypes. Another issue could be that aligning the model with one set of people causes it to misalign with others, which is reflected in benchmark evaluation.
Finally, some have criticized OpenAI for classifying the study as an “alignment” paper, claiming that human tuning isn’t the same as alignment. Another, more serious critique is instead that aligning the model with hired labelers: OpenAI researchers and OpenAI users, isn’t true alignment. The true challenge is training models to deal with circumstances where groups disagree in their preferences (rather than finding common ground averages), especially when prejudiced minorities, who are always targeted by these models, are at risk.
When it comes to Artificial Intelligence and training is always hard to find objectivity when we talk about values like honesty or when we have to find harmfulness in some behaviors. Although we could try to detect good and bad intentions by training A.I. through humans, we are going to inevitably fail because people themselves can’t be objective all the time and we can’t even find the perfect sample of people who represent well what’s right or wrong. Therefore we maybe need a continuous training by different people hoping the achievement of an increasing better humanity will converge in a better A.I. training.
Source towardsdatascience.com

{kind=link}